





AI最疯狂的一周,该知道的8大共识都在这了

一场千人 AI 盛会,讲透国产 AI 的真相。
短短 8 天,全球 AI 领域发生的重磅新闻,发布节奏之密、信息密度之高、资金体量之大、涉及玩家之广,堪称惊心动魄。
从 4 月 16 日到 24 日,Anthropic Claude Opus 4.7、阿里 Qwen3.6-Max、月之暗面 Kimi K2.6、OpenAI ChatGPT Images 2.0、蚂蚁 Ling-2.6-flash、小米 MiMo-V2.5-Pro、腾讯 Hy3、OpenAI GPT-5.5、DeepSeek-V4 等 9 款前沿模型扎堆发布。
同一时期,亚马逊和谷歌相继表示分别拟向 Anthropic 投资 250 亿美元和 400 亿美元,马斯克 SpaceX 宣布拟以 600 亿美元收购 AI 编程独角兽 Cursor,DeepSeek 启动外部融资的传闻亦沸沸扬扬。
这一周大事串联起来,映射出5个清晰的趋势:
AI 竞争的核心战场已从“聊天”转向“干活”;
中美 AI 头部梯队基本形成,并在持续冲锋;
中国 AI 在开源和成本效率上展现出独特竞争力;
算力基础设施将成为影响 AI 竞赛节奏的关键因素;
“投资+竞争+合作”的新型多重产业关系正在确立。
值此期间,4 月 21 日至 22 日,2026 中国生成式 AI 大会(北京站)圆满举行。
大会由智东西主办、智猩猩联合主办,集结 73 位产学研投嘉宾,围绕“奔赴 AGI 重塑未来”主题,通过 1 场开幕式、3 场专题论坛、6 场技术研讨会,全景式解析 AI 产业的产业脉络、创新范式、Token 经济与中国机会。
议题跨度很大,从大语言模型、多模态模型、世界模型、智能体、AI 眼镜等前沿模型与应用,到数据、芯片、存储、通信、云服务等基础设施。
嘉宾们各抒己见,聊痛点,讲预判,立足当下,探讨未来,分享内容之丰富,非常挑战大脑容量。
一个明确的共识是,国产 AI 战场,已经从模型层扩展到生态层。
我们整理了开幕式和 3 场专题论坛的嘉宾们分享的重点信息,希望能对你有启发。
1、大模型怎么变强?达到垂域专家水平只是时间问题
2、小心养龙虾、买token 踩坑!聊聊大模型服务商不会告诉你的那些事
3、从 Claude Code 泄露代码,总结6个反共识观点
4、OpenClaw 之后,智能体时代的中国机会在哪里?
5、世界模型的多重路径:视频生成、多模态原生统一、3D 生成
6、Token 消耗量爆发,国产 AI 基础设施如何协同与进化?
7、大模型下半场,竞争焦点变成场景、数据、品味
8、从“龙虾”、AI 眼镜到 token 管理,拆解国产智能体落地潮
01. 大模型怎么变强?达到垂域专家水平只是时间问题
在开幕式上,中国人民大学高瓴人工智能学院教授赵鑫的演讲围绕一个根本问题:大模型怎么变强?
首先,大尺寸模型仍具有显著的性能优势,通过预测下一个词的预训练范式能够建立非常强的基础能力;在后训练方面,一个重要方向是 RLVR(基于结果监督的强化学习),能针对垂直领域提升模型能力,提供了超越“预测下一个词监督训练”的另一条Scaling路线,为复杂智能体环境的训练构建了可行的训练途径。
接下来,让大模型学会使用工具,如搜索信息、用编程解决问题等。代码执行增强的推理链,解题过程更简洁清晰,显著提升推理效率。
随着任务复杂度提升,模型需要进行大量轮次的交互,上下文窗口的管理成为挑战。有两种思路:一是通过模型自主压缩上下文,二是使用文件来作为上下文的外部存储介质。
在多模态深度搜索场景中,图片、视频等内容若直接 token化,会急剧膨胀上下文。一个解决方案是搜索结果先写入本地文件系统,同时生成简短摘要进入上下文窗口,后续需要时再按需加载,从而实现稳定的百轮级多模态搜索。

▲赵鑫
给大模型一台虚拟电脑(如终端/沙盒),可在非代码领域激发通用能力。
大规模训练需要大量多样化的环境,手动创建几万个环境不现实。近期研究显著增加了智能体类数据的引入,比如 DeepSeek-V3.2 在强化学习中显著增加构造的智能体任务和配套环境,这些仿真环境旨在低成本高效合成大规模训练数据。
怎么模拟复杂环境呢?大多数智能体操作仅需轻量的沙盒,如果采用基于 Docker 环境训练代码智能体的方法,可扩展瓶颈会集中在 Docker 执行层。此时可以用大模型代替 Docker 提供执行反馈,来减少对真实 Docker 的创建需求。
当前多智能体系统的核心挑战在于长程任务的稳定性,这需要制定合适的工作流。
对此,高瓴人工智能学院开源的 AiScientist 系统,将决策层与专家层分开,编排器专注阶段级决策,专家负责复杂子任务,让文件成为智能体协调“总线”,从而实现复杂编排与协作。
最后,赵鑫教授分享了三点预判:
1、模型能力扩展受限于人的认知。目前可利用算力的方式仍然有限,突破需要新的扩展范式。
2、大模型达到垂直领域专家水平只是时间问题,广义 AGI 仍然困难。类似“下一个 token 预测”和 RLVR 这样的重要训练扩展范式,估计还需要出现 1~2 次,才能推动广义 AGI 的实现。
3、大部分创新是工程创新,AGI 需要更多本质创新。模型能力与 Harness 的发展是螺旋上升、互相适配的,基础设施补强模型短板,模型提升后再推动基础设施演进;技术难以形成持久的护城河,人才、数据更为关键。
02. 小心养龙虾、买 token 踩坑!聊聊大模型服务商不会告诉你的那些事
清程极智联合创始人师天麾点破了当前 token 行业乱象——买 token 藏有很多坑。
同一个模型,在不同服务商处购买,效果不同,最终花费不同,服务质量可能差别巨大。
有次评测,他们发现某个服务商的模型明显有问题,问过后,服务商承认用的是 int4。这种量化能把成本压得非常低,但是模型效果很差。
提供同一个模型,报价便宜的服务商反而可能用起来总成本更高,因为缓存命中率不一样。
缓存命中率是一个非常影响总成本的指标。各家服务商因为技术不同,缓存命中率相差很大,好的能超过 80%,差的缓存几乎跟没有一样。
但服务商不会告诉客户这件事。

▲师天麾
AI Ping 团队对国内 30 多家服务商的 600 个大模型 API 服务进行了测试,服务商包括模型厂商、互联网大厂、云上市公司和 MaaS 厂商。
根据他们的测试,大型服务商(如云厂商、电信运营商),在提供相同的模型服务、价格相近的情况下,各家服务性能可能相差5倍甚至更多。
他们观察到,近期国内各家服务商的服务质量,相比去年年底明显差了很多。许多服务商不能给中小客户保证质量,响应慢、有明显性能问题。
“养龙虾”等行业热潮火爆,导致 token 供不应求,又贵又慢。token 服务又是黑盒,行业发展很快,也很乱,那怎么选对 token 服务商?
师天麾安利了清程极智研发的 AI Ping:它对用户关心的大模型服务指标做了全面评测和汇总,并提供筛选排序和智能路由功能,以便用户对不同大模型 API 服务进行 7x24 评测和按需调用服务。
03. 从Claude Code 泄露代码,总结 6 个反共识观点
Pine AI 首席科学家李博杰重点聊了聊从 Claude Code 泄露代码中的收获。
在他看来,Claude Code 源码里的五层权限判断、错误恢复、安全防护工具集、反蒸馏防御机制等设计,还有用做研究的方法做产品,都非常值得学习。

▲李博杰
李博杰还分享了从中总结出的 6 个反共识观点:
1、图形界面(GUI)的价值将逐渐降低,软件价值正从界面转向数据治理,没有数据壁垒的 SaaS 大概率被干掉。
智能体阅读和思考速度远超人类,但操作 GUI 的速度比人慢,因此 GUI 对智能体不友好。
Claude Code 就是典型的 GUI 价值低、业务逻辑与数据治理价值高的产品形态,51 万行源码里没有一个产品级 GUI。
2、上下文是人类避免被 AI 取代的护城河。
AI 能访问的上下文远低于一个人类员工,比如吃饭时聊出来的设计目的、屎山代码里的坑、没表达出来的内心想法。
告诉 AI 合适的上下文,也是用好AI的关键。
3、AI 原生组织,本质是用AI替代传统的“上传下达”层级结构。
Anthropic、Kimi 等公司的中层大幅压缩,实现良好的上下文共享,让高层看到基层信号,让基层直接看到战略上下文。
“砍掉高层的手脚,砍掉中层的屁股,砍掉基层的脑袋”,这个段子在AI原生公司中不成立了。
4、哪些人会被 AI 替代?
头部(高价值决策与创造)和尾部(与物理世界深度集成的工作)相对安全,腰部(执行型、无泛化能力的标准化工作)最为危险。
AI 是技术能力的放大器,推动非技术能力的重要性比重上升。学习新知识、适应新场景的能力很关键。
一人公司(OPC)不是一个人能开发 App,大多数独立开发者的瓶颈不是写不出代码,而是获客、信任、运营这些稀缺能力。
5、“模型即 Agent”远远不够。
真正的智能体里有一堆复杂的 Harness来 兜底解决模型搞不定的部分,代码量远超工具+提示词本身。只有模型公司同时控制应用层和兜底工程。
Agent=Model x Harness。大模型提供“大脑”,而 Harness 提供了“手脚”和“缰绳”,包括上下文怎么给、工具怎么调用、出错怎么恢复、安全怎么保障、缓存怎么共享、并行怎么协调等。
6、应用层公司的护城河在技术之外。
Harness 里的“屎山”反映了模型内部模型团队和应用团队之间的张力,是应用层短期的技术杠杆,但是技术优势会被模型公司的飞轮吃掉。
顶尖模型的差距还会继续拉大,中端模型将趋于商品化。应用层公司的长期护城河是数据、渠道、拍照、用户信任、网络效应等等。
04. 高端对话:OpenClaw 之后,智能体时代的中国机会在哪里?
高端对话环节由智东西联合创始人、总编辑张国仁主持,三位嘉宾均在智能体领域颇有建树,分别是香港大学助理教授&博士生导师、Nanobot 团队负责人黄超,网易有道 LobsterAI 项目负责人、智能硬件研发负责人王宁,峰瑞资本投资合伙人陈石。
黄超团队的 Nanobot 开源项目仅用约 4000 行代码,实现了原版 OpenClaw 用 43 万行(现已超百万行)代码的核心功能。
王宁团队的 LobsterAI 是国内大厂第一个开源的桌面级智能体产品,1 周获得超过 3k star,还被 OpenClaw 创始人 Peter Steinberger 发文夸赞。
陈石有超过 15 年的连续创业经历,曾任阿里高管,曾经是一名快乐的程序员和用户增长专家,如今也是一位对 AI 行业深入跟踪观察的投资人。

▲从左到右:张国仁、黄超、王宁、陈石
1、智能体行业变化太快,2026 年会是标志性一年
黄超:智能体演进太快了,去年底 MCP 普及到现在的 Skill 和 Harness,仅三四个月。2026 年可能是智能体生态爆发的一年,智能体的能力边界扩展需要整个 Skill 生态、环境交互体系的协同成熟。
王宁:OpenClaw 大大加速整个智能体落地进程,各行业都认识到智能体能帮企业干活、提效、挣钱。去年 Chat 类产品一直在找营收来源,比如靠广告,其实没挣太多钱。今年可能是 Agent 产品商业化爆发的起点,真正能向用户和企业收费的Agent产品出现。
陈石:从去年下半年到今年年初,AI 行业最大的变化是智能体开始在应用层挣钱了,不再只是英伟达挣钱。OpenClaw 开启新的智能体范式,今年可能是 AI 真正能被大众用起来的一年。
2、工程粗糙却范式创新,OpenClaw 为何能改变AI行业?
黄超:它的交互模式是创新的,看似简单的设计,让社区感受到智能体更加主动。此前的智能体工具感太重,OpenClaw 点燃了人们对”通用个人助手”的长期期待。
王宁:类比移动互联网早期,很多 App 最初都是小团队做的、很粗糙,但商业模式和用户场景满足得很好。OpenClaw 做了类似的事。
陈石:它也许在工程上还比较粗糙,但应用范式创新对行业影响非常大。
3、OpenClaw 降温了?现象级产品完成历史使命
陈石:当前 OpenClaw 本身可能并不是一个特别优质的产品,但它是一个象征意义重大的现象级产品,它的核心定位是在“开放域里做无终点的事”,这是人类历史上是第一次让普通用户用 AI 在数字世界中进行不设限制的探索。之前的智能体产品包括 Claude Code、Claude Cowork 和 Manus 都不在这个定位。OpenClaw 更像是普通人心中的“数字助手”或者“数字伙伴”的形象。
王宁:DeepSeek 也是大概火了两个月,但之后它让“推理能力”快速渗透到了各行各业。OpenClaw 也有点类似,它也加速了 Agent 产品走向更广泛的行业应用。热度会回落,但能力渗透一旦开始,真正的行业价值才刚刚开始释放。
黄超:降温可能是因为 token 烧得多,事情做得没达到预期。OpenClaw 完成了它的使命,建立了智能体在用户中的心智。热度下去说不定是好事,可以让大家沉淀下来思考:什么时候需要让 OpenClaw 变成真正能帮我们搬砖的打工人。
4、高质量 Skill 很少,Harness 极其重要
黄超:虽然很多 to-use 模块从 MCP 进化到 Skill,Skill 像 MCP 工具调用说明书,但 MCP 存在的问题,Skill 也存在,比如质量控制不好。
Skill 很多,但高质量的 Skill 很少,检索与匹配效率低下。未来需要专门的平台对高质量 Skill 进行管理和分发。
Harness 与模型能力相辅相成。长程任务是一大工程挑战,上下文极度爆炸、实时环境交互复杂、中断现象普遍,Harness 显得极其重要。
5、当前 AI 行业的商业逻辑与创业建议
陈石:当前 AI 行业的商业逻辑与移动互联网时代有根本性差异,不能做线性外推。
移动互联网时代有个著名的商业模式是“羊毛出在猪身上”,免费获客、广告变现,但其前提是单用户使用成本很低。但 AI 产品用户使用越多,Token 消耗越大,当前的成本远高于广告的 eCPM,在商业上根本跑不通。
未来 AI 行业大部分的收入将被t oken 生产与分发环节的公司收走。智能体能够独立存在的机会,在于广泛收集人类的上下文(操作轨迹、使用场景、业务逻辑、行业知识),形成模型厂商抢不走的数据壁垒,用户用得越多,越依赖,护城河越深。
建议早期智能体创业公司优先考虑“前向收费”,做不到就不要盲目扩张,说明还没拿出能让用户愿意付费的产品。另一个建议是“软饭硬吃”,利用中国制造业供应链优势,在通过软件掌握用户需求和产品技术积累后,做出软硬件一体的产品,这类产品到海外很能打。
6、中国版下一代智能体框架,机会在哪?
王宁:OpenClaw 给国内大模型厂商带来了新的机会,国内模型价格大概只有海外模型的 1/10,能力上又相差无几,特别适合”龙虾”场景。
企业级 Agent 也有一些新的机会。国内已有不少国企和私企寻求将智能体产品在公司内普及,并与内部系统打通,需求涵盖办公自动化、OA、财务、ERP和数据安全等场景。
黄超:国内一直有应用创新基因,有信心国内机构能打造出下一代真正成为打工人的智能体。
05. 世界模型的多重路径:视频生成、多模态原生统一、3D 生成
语言只是人类感知世界的通道之一,图像、声音、3D 空间等多模态才构成了物理世界的原始语言。
在世界模型方向,三位嘉宾从不同角度的分享,拼在一起很有意思。
1、智象未来姚霆:多模态创作智能体走向全模态,即将发布 HiDream-O1-Image 图像大模型
智象未来(HiDream.ai)联合创始人兼 CTO 姚霆分享说,随着语言模型与多模态大模型能力飞速跃升,多模态创作智能体的技术底座已基本成型,并将走向全模态世界模型。

▲姚霆
通用智能体的核心能力是:上下文管理、工具调用、开放域对话与任务自动化,典型场景如定闹钟、订外卖、制定旅行规划。
在此基础上,多媒体创作智能体还需解决专业性、协作性、一致性与可控性问题。其典型任务包括图文内容创作、视频高光时刻剪辑、从故事到脚本到分镜再到成片的完整视频生成链路等。
当前多模态生成模型的主流架构存在一个缺陷:文本编码与视觉编码相互独立,信息交互单向,且视觉 VAE 编码器会造成信息损失。
下一代架构的核心思路是将所有模态统一输入到一个 Unified Transformer,同时完成理解与生成,实现无损编码+原生交互,走向“原生全模态”。
基于上述架构,智象未来即将发布 HiDream-O1-Image 系列模型,并将开源一个8B参数量的版本,该开源模型在 6 项基准测试中达到与 FLUX.2、Qwen-Image 同量级甚至略优的水平,并适配本地部署和低代码智能体调用场景,同步,智象未来以此架构为基础,逐步构建智象下一代世界模型。
围绕多媒体创作需求,智象未来提出 HiDream Agent OS 基础设施,分为工具层、Skill 层、Harness 层,可实现工具、创意、经验可复用。
该团队已推出全能创作智能体 vivago Agent、视频剪辑智能体 HiClip Agent、影视创作智能体帧赞等智能体工具,其中帧赞已累计制作 AI 短剧漫剧超过 5000 分钟。
姚霆认为,多媒体创作智能体的终极目标,是让创作回归灵感本身,将重复性、工具性的工作交给智能体,让人专注于真正属于人的创造力。
2、北京大学袁粒:大语言模型快到头了,多模态原生统一才是未来方向
北京大学深圳研究生院助理教授&研究员、博士生导师袁粒认为,大语言模型已逼近极限,多模态原生统一才是未来,没有多模态原生统一,就没有真正的世界模型。
同时,他认为将 token 翻译成“词元”是默认大模型以语言为中心,这也是为什么 GPT-5 数不清人有几根手指,大模型只专注语言这一模态,无视其他物理模态(比如视觉),无法真正让其走向物理 AI。
多模型协作的方式在数字世界尚可运行,但在物理世界存在两大致命缺陷——高延迟和信息损失。以机器人搬水为例,这个任务对人类来说很简单,当前绝大多数机器人仍无法流畅完成。
人类大脑构建的世界模型天然是多模态、统一的。当前所谓的“世界模型”,本质上仍是单模态模型。只有实现多模态原生统一,才能构建出真正理解物理世界的世界模型。

▲袁粒
构建多模态原生统一架构,面临五大技术挑战:如何定义“原生多模态”、自回归建模与扩散建模融合、多模态视觉编码器统一、消解模态冲突、训练数据清洗和标注等。
袁粒团队在多模态理解、生成、架构与统一方向均有一些代表性工作。例如,其 Helios 原生实时视频架构采用自回归+扩散 Transformer,无需 KV Cache 等加速技巧,单卡可达近实时生成。
袁粒还展示了由其课题组多模态统一方法生成的图像,无论是现实复杂场景生成还是数学虚拟生成都远超其余同期模型水平。
3、VAST 梁鼎:3D+视频,或许才是世界模型的终态
VAST CTO 梁鼎分享说,3D 生成模型正在从单点能力走向完整的生产管线覆盖,高模与低模两条关键技术路线并行发展,Tripo 大模型在游戏、工业、家装、潮玩等行业已产生实质影响,VR/XR 与具身智能仿真环境的建设也高度依赖3D能力。
围绕这两条技术路线和对应生产需求,VAST 已经推出了行业 SOTA 的两款 AI3D 大模型:Trpo H3.1 和 Tripo P1.0。
Tripo H3.1 追求高视觉质量与贴图精细度,适用于 3D 打印、工业设计、实体制造等对视觉还原度要求高、无需实时渲染的场景。
Tripo P1.0 专为实时渲染引擎设计,核心优势包括直接从图片生成低模、生成速度快、生成结果具备拓扑友好和 UV 友好的特性等,适用于游戏管线制作、UGC 生成式玩法、移动端 3D 资产生成等。

▲梁鼎
单个资产的生成只是起点,完整的3D制作管线还涉及部件拆分、贴图编辑、骨骼绑定等环节。目前低模上的拆件与绑骨能力、场景级别的自动化生成、从视频中提取动画的能力等仍待突破。
当前世界模型的构建存在两派:视频原生派与 3D 原生派。这与早年 3D 生成领域 2D 升维与 3D 原生的路线之争很相似。视频路线的优势是生成效果好、训练数据充足,但存在长时序记忆难、多人一致性难、推理成本高等局限性。3D路线的难点在于制作门槛与画质上限。
梁鼎认为,两条路线最终很可能走向融合,世界模型的终态或许是 3D 与视频共同驱动的统一方案, 3D 在其中将扮演不可或缺的结构性角色。
06. Token 消耗量爆发,国产 AI 基础设施如何协同与进化?
无论是前沿模型训练,还是蓬勃发展的 AI 应用推理浪潮,都对 AI 基础设施中的计算、存储、互连架构提出更高的协同要求,算力层也正从成本中心演变为以 token 为计量维度的利润中心。
如何推动 token 成本持续下降,是摆在 AI 基础设施供应商们面前的共同考题。
在AI 算力基础设施专题论坛,嘉宾们从计算、存储、网络、云服务等不同维度,分享推动国产 AI 算力走向普惠的可行路径。
具身智能芯片方案如何支撑机器人集群算力需求?企业使用算力面临哪些主要痛点?芯片架构设计如何提升能效比?谁是提升 token 生产效率的隐形障碍?国产 AI 算力生态怎样形成聚合?来听听他们的答案。
1、芯桥张鑫:具身智能需要跨节点算力协同
芯桥半导体解决方案副总裁张鑫谈道,随着具身智能机器人从单点执行走向群体智能,算力问题也从单点性能提升转向跨节点协同与分层调度。
受制于电池续航、板卡面积等条件,单台机器人的算力存在物理上限。对此,芯桥半导体提出了五位一体、软件协同的“大脑-小脑-肌肉”架构,通过分布式方案来支撑机器人集群算力需求。
其中,在决策层,X200 芯片提供 682TOPS 峰值算力、819.2GB/s HBM2E 带宽,支持 50-100 台机器人协同作业;在感知层,S200 边缘计算芯片提供 128GB 显存、66W 被动散热、4800FPS 极速解码,以便机器人实时处理感知数据。
芯桥还提供宏观任务调度与集群管理、精细单元控制与实时状态监控等功能。

▲张鑫
2、Hammerspace 王殿清:别浪费了 GPU 服务器本地存储
Hammerspace 资深解决方案架构师王殿清说,AI 产业正从模型军备竞赛转向推理效率、基础设施重构的系统性竞争。存储基础设施存在数据分散、传输费时费力等不便,GPU 服务器本地存储一直未得到充分利用。打破存储孤岛是 AI 走向大规模落地的关键基础条件。
高性能存储设备的速度远超外部存储,却因为存储孤岛、不受保护、难以在本地存储和外部共享存储间移动数据等问题,一直未被使用。以千节点集群为例,每节点数百TB的本地盘如果仅作临时缓存,浪费的存储空间可达数百PB。
Hammerspace Tier 0 技术可将 GPU 服务器磁盘配置为一个或多个 NFS 导出,由软件统一纳管,形成为一个全局可见、共享的存储层。Meta 便基于标准架构,利用现有服务器、网络、GPU,节省了多达数百万美元。

▲王殿清
3、GMI Cloud 蒋剑彪:今年算力市场呈四大变化
GMI Cloud 中国区总裁蒋剑彪分享了 2026 年 AI 产业的 4 大核心趋势:1)推理成 AI 基础设施的主要市场;2)智能体推动 token 消耗千倍级增长,主要客户普遍提前锁定算力资源;3)AI 编程引爆一人公司(OPC)模式,成 AIGC 应用下一个关键增长引擎;4)智算中心从存储仓库转向算力工厂,追求极致算力密度、能效比与 token 吞吐量。
GMI Cloud 是一家领先的 AI Native Cloud 服务商,是全球七大 Reference Platform NVIDIA Cloud Partner 之一,拥有遍布全球的数据中心,为企业 AI 应用提供最新、最优的 GPU 云服务,为全球新创公司、研究机构和大型企业提供稳定安全、高效经济的 AI 云服务解决方案。
蒋剑彪预告说,GMI Cloud 面向龙虾智能体(Claws Agents)的全新生态产品 The GMI Claw Marketplace 即将上线,将面向企业用户和 AI 开发者,提供一站式端到端解决方案。

▲蒋剑彪
4、九章云极张磊:让算力像水电一样管够
九章云极 DataCanvas 解决方案专家张磊总结说,企业使用算力有三大痛点——买不起、用不满、管不好。九章云极以 AI 原生基础设施与智算云为核心,希望将算力转化为标准化的普惠AI资源。
作为普惠算力的核心载体,九章云极提出了算力服务单位“度”,定义 1 度算力=312TFLOPS*1 小时,以便将不同算力卡通过统一技术指标换算为一个标准度量单位。用户可按需购买、秒级启用,仅对有效计算时间付费,彻底避免了硬件资源闲置与浪费,显著降低了 AI 研发与使用的门槛与总拥有成本(TCO)。
面向 AI 原生时代,九章云极打造的 Token Factory 将算力从成本中心转化为可创造业务价值的增长中心,以 token 吞吐量作为核心效率指标,直接支撑企业 AI 竞争力提升。智算云平台上打造了 AI 开发一站式赋能与模型调用服务能力,并支持跨区域、跨厂商的算力资源统一调度与智能编排,为大模型训练、推理、智能体开发等全场景提供高效、稳定、弹性的算力支撑。

▲张磊
5、DDN 李凡:疏通 AI 算力工厂的数据管道
DDN 中国技术总监李凡谈道,AI 基础设施的竞争已从单一硬件性能转向系统工程能力,英伟达从 2016 年起就在其内部集群采用 DDN AI 数据智能平台。由 DDN 提供支持的 AI 工厂,GPU 利用率可达 99%,显著降低电力消耗和空间占用。
KV Cache 是当前分布式推理场景的存储热点,对动态扩展性与元数据性能的要求超过峰值吞吐。DDN EXA/Infinia KV cache fabric 方案可 30 倍加速推理和智能体,同时保障低延迟和低成本。

▲李凡
DDN 虽为美国公司,但中国本土研发团队已从数人扩展至 80 人,并深度参与国产算力生态,正与国产网络、国产算力、大模型厂商合作,推进系统级工程实践。
国产 SSD 供应商大普微旗下多款大容量 QLC 产品已完成 DDN 全平台测试认证,支持智能体数据大容量存储,提供更快的 token 响应。双方将继续深化合作,推出更强的 PCIe 5.0 SSD 产品组合。

▲大普微 DapuStor 高级总监黄明达
6、光羽芯辰姜汉:存算一体翻倍提升 AI 芯片能效比
光羽芯辰产品市场总监姜汉认为,端侧 AI 生态不能由单一价值链玩家独立推动,需联合从操作系统层到 App 层的全栈合作伙伴共同构建。作为一家端侧 AI 大模型芯片创企,光羽芯辰已与头部手机厂商、头部 PC 厂商达成商业合作,未来还考虑应用于具身智能机器人场景。
光羽芯辰是一家由 AI 头部企业与存储头部企业等合资设立的公司,已完成多轮融资。该公司提出了将存算一体架构与 3D 异构集成技术相结合的端侧 AI 解决方案,并率先将该方案实现于 AI 芯片产品中。
相比传统架构,其存算一体架构可实现5倍能效比、10 倍带宽,响应延迟降至 1/10。光羽芯辰也提供硬件级可信执行环境,并与 OpenClaw 等框架无缝集成,以加速端侧 AI 应用落地。

▲姜汉
7、上海 AI Lab 蔡政:为国产 AI 芯片快速搓出高性能算子
上海人工智能实验室 DeepLink 团队工程师蔡政强调,高性能算子体系是英伟达生态的核心护城河,也是国际AI竞争的核心战场,将各类基础设施、模型能力、芯片技术、应用场景协同,关键在于一个性能好、覆盖广、可演进的算子体系。
目前国内算子开发面临门槛高、调优难、架构差异大且迭代快、迁移易损失性能等挑战。
2025 年 KernelBench 首次系统性评估了大模型自动生成高性能算子的能力,结论是即使最先进的模型在 One-shot 场景下,首轮算子通过率(编译正确+精度正确)普遍不超过 90%,甚至剔除掉生成了但是没有实际运行的结果之后,矫正后的算子通过率普遍不超过 55%。
对此,DeepLink 团队提出 KernelSwift 智能体进化架构,更充分地探索 Kernel Search Space 和利用 Test Time Compute。在 KernelBench L1/L2/L3 测评中,该系统在英伟达平台上整体性能领先,并且生成的算子代码已经应用于生产级推理引擎 SGLang 和 LMDeploy。
KernelSwift 通过 DeepLink 自研 AI 编译器 DLCompiler 的协同,实现了对华为昇腾、沐曦、寒武纪、海光、平头哥、天数智芯等主流国产芯片的支持,跨平台兼容率达 90%。

▲蔡政
8、探微芯联张羽:打造对标英伟达 NVLink 的国产互联方案
探微芯联超节点与推训平台技术专家张羽谈道,大模型对显存有极致要求,单芯片扩展已逼近物理瓶颈,Scale-up 超节点是未来长期的主要发展方向,通过高性能互联突破单 GPU 计算容量、存储容量和访存容量的限制。
探微芯联以 scale-up 互联资源池为核心,通过自研的 ACCSwitch 芯片与 XPU 端的 ACCLink,将计算、内存、存储、CPU 四大资源池整合成一个统一的计算系统,并围绕芯片提供驱动软件栈,形成 scale-up 域互联整体解决方案。
其方案可帮助计算卡厂商、DRAM 厂商、存储厂商构建对标英伟达 NVLink 生态的国产 scale-up 超节点系统。

▲张羽
9、圆桌讨论:Token 爆发元年,国产 AI 算力如何从可用到好用?
AI 算力基础设施专题论坛的圆桌讨论由千芯智算董事长陈巍主持,三位嘉宾分别是芯桥半导体解决方案副总裁张鑫、DDN 中国技术总监李凡、探微芯联超节点与推训平台技术专家张羽。
陈巍谈道,根据国家统计局的数据,今年3月,我国日均token调用量已突破 140 万亿,较 2024 年初的 1000 亿增长超过 1400 倍。AI 推理已不再是单纯的堆卡堆算力,而是进入 token 工厂时代,每生成一个 token,都在极致考验计算芯片、存储、互连架构的协同。
随着推理时代到来,传统基础设施已无法满足智能体和长链路任务的需求。站在 token 爆发元年的风口之上,国产 AI 算力如何从可用迈向好用?这个议题非常具有现实意义。

▲从左往右:陈巍、张鑫、李凡、张羽
几位嘉宾分享的一些共识观点包括:
(1)token 成本是国产算力从可用到好用的关键命题,更低成本、更高 token 产出效率是前提。
(2)系统工程化协作是短板。发展计算、存储、互联、网络、运维的一体化工程能力,才能真正释放 token 工厂的潜力。
(3)中国团队在模型量化等软件层的能力已接近或超越国际水平,制程、良率等硬件层差距客观存在,场景化需求可能会抹平部分技术差距。
(4)Scale-Up 超节点是确定性长期趋势,是国产 AI 算力生态整合的关键抓手。
(5)AI 下一个爆发点尚待观望。未来 Agent 长时序主动执行将改变计费体系,对硬件成本、集群效率的要求将更严苛。
计算方面,张鑫谈到 AI 芯片设计正向定制化模型需求靠拢,例如针对矩阵计算做专项硬件加速(参考 Groq 思路),可同时实现资源节省、性能提升与成本下降,建议加强芯片层与落地场景的沟通,推动硬件针对专属场景的定制化改造。
在他看来,智能体落地不是单一模型运算,而是多模型在不同场景、不同节点、不同步骤的分场景拆解,是否需要专用芯片支撑仍在探索中。
存储方面,李凡提出存储架构割裂(HBM、DRAM、SSD 各自孤立)是当前制约 token 生产效率的隐性障碍,只有打通才能真正释放算力。
他认为,中国AI推理基础设施的 token 输出效率已超越国外水平,现阶段主要问题是工程配合与生态整合不足,仍处于堆卡堆资源的初期阶段,缺乏计算、网络、存储、运维的系统级协作。
通信方面,张羽提到计算、存储、互联三者之间存在此消彼长的平衡难题,把存储做成 HBM 类混合存储可行,但会将压力转移到通信侧。
他建议,芯片内部的平衡、芯片间互联的平衡、存储的平衡三者需统一建模,建议构建性能建模工具,拆解大模型推理任务中的算子(通信算子、访存算子、计算算子),预估各阶段计算量、访存带宽需求,寻找计算与通信细粒度 overlap 的最优点,从而实现最大化性能。
张羽预计未来 3~5 年,计算卡厂商、存储厂商将逐步融入统一的 Scale-Up 超节点生态。
07. 大模型下半场,竞争焦点变成场景、数据、品味
在大模型专题论坛上,6 位演讲嘉宾分别从模型能力演进、基础设施重构、行业应用落地等维度展开分享。
模型层面,“任务完成度”成为厂商关注重点,即能否在真实场景中交付稳定、可靠的结果。
基础设施层面,AI训练和推理需要全新的数据存储基础设施,AI token 工厂的每一层都需要被重新设计。
应用层面,“理解场景”与“理解人”成为 AI 落地的必修课。大模型不能再仅仅满足于简单生成,而要能理解语言之外的意图、业务逻辑乃至心理。
1、智谱李子玄:Long Horizon 成 AI 编程新重点
智谱Z.ai负责人李子玄认为,AI 编程的竞争焦点正从单点生成转向“Long Horizon(长程任务)”能力。
他澄清,Long Horizon 并非长度的比较,而是要求模型执行任务的过程中保持目标与逻辑不失真,能从失败中迭代优化,交付高质量的结果。
GLM-5.1 正是体现这一能力的模型。
结合自身实践,李子玄提出,如今的 AI 研究员要像产品经理一样懂场景,评测已经成为引领模型发展的重要管理方法。而在 PMF 方面,企业需要进行前瞻布局与技术储备,才能在技术拐点到来时捕捉机遇。

▲李子玄
2、阿里云王作书:AI 将带来全局性机遇
阿里云千问大模型解决方案资深总监王作书观察到,大模型已走过学术奠基、产业投入阶段,步入了商业加速期。当前,模型推理能力显著增强,多模态融合与开源生态日趋成熟,AI 正从“聊天”进化为核心生产力。
为此,阿里巴巴成立 ATH 事业群,围绕“创造 token、输送 token、应用 token”升级了其 AI 战略,目前已围绕着文本、多模态等多条主线研发模型,最新成果包括 Qwen3.6 系列模型、Qwen3.5-Omni、万相 2.7 等。
王作书透露,阿里大模型团队未来的三大技术目标为提升知识规模和效率、增强智能水平和多模态融合。
她还提出了价值四象限的概念:未来 AI 将创新力/劳动力为纵轴、产品力/生产力为横轴持续扩展,推动消费电子、生产系统等升级,带来全局性机遇。

▲王作书
3、焱融科技张文涛:AI 竞争本质是数据竞争
焱融科技 CTO 张文涛观察到,AI 的竞争本质上是数据的竞争,无论是训练还是推理,都对高性能、低延迟、去孤岛化的数据存储基础设施有着迫切需求。
焱融应对上述挑战的思路是打造一套全栈AI存储解决方案。具体来看,该公司的全闪存储一体机产品 F9000X 采用了冷热数据智能分层、弹性网络等技术,使得每GiB/s带宽成本下降 60%,并在 MLPerf Storage v2.0 测试中排名榜首。
面向推理场景,焱融推出了涵盖 DRAM 到本地盘再到远端共享存储的多级 KVCache 缓存管理系统 YRCache,并通过智能预取、异步卸载、零拷贝等技术实现加速。
同时,焱融科技也提供了企业全域数据管理平台 DataInsight,可以统一纳管分散在各处的数据孤岛,形成统一视图,并支持自定义数据流向,给大模型训练提供便利。

▲张文涛
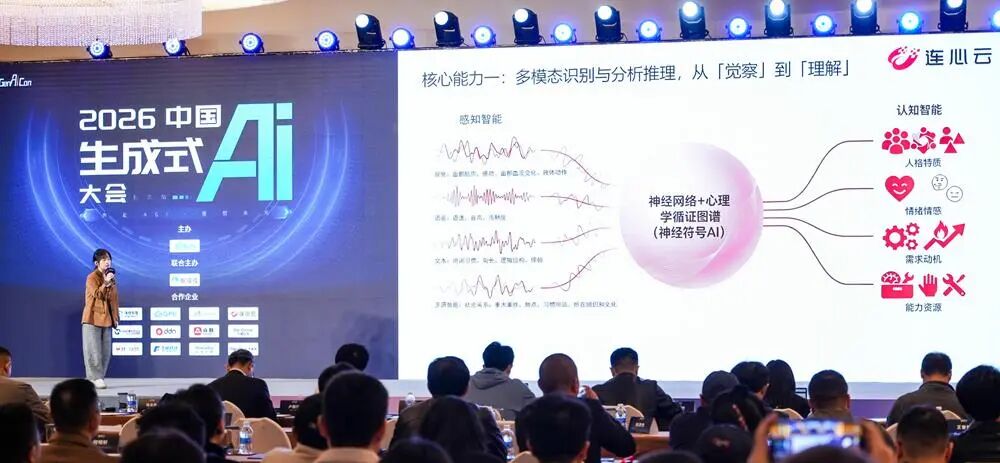
4、连信数字/连心云黄杏:理解“人”是 AI 进入真实世界的关键
连信数字/连心云洞见研究院院长黄杏认为,现实中的管理者、面试官、家长等群体,常常需要借助语言之外的信息来理解他人。同样,当前 AI 虽擅长处理语言,但若想真正融入真实世界,就必须理解人心。
连信数字洞见研究院汇聚了心理学、算法与大数据的跨学科精英,“洞见人和”人本世界(心理)大模型以全球多源数据为底座,通过多模态感知与神经符号 AI 的深度融合,改变了传统的“经验驱动”分析,通过智能循证分析实现了对人类的深度洞察与全面刻画。
这一模型已在公安、教育、司法、安全生产等行业落地实战,并已覆盖 20 多个省市,累计 2000 万+人群。
在大会现场,黄杏宣布,即日起,连信的所有模型能力与原生 Agent 将通过连心云能力平台正式对外开放,赋能更多行业场景。
▲黄杏
5、上海 AI Lab 张鸿杰:统一多模态模型的关键不是技术选型
上海 AI Lab 青年研究员张鸿杰介绍,目前统一多模态大模型主要采用纯自回归、纯扩散与其他融合上述架构的折中方案。但他认为关键不是选路线,而是在统一上下文中实现理解与生成各有所长,让不同模态采用最适合的预测方式。
基于这一判断,上海 AI Lab 研发了 InternVL-U,一个 4B 参数的统一多模态大模型。具体来看,InternVL-U 拥有统一上下文,但目标照模态实现自适应。这一模型采用 InternVL 3.5 的主干完成理解和推理,并把像素合成交给 MMDiT,从而实现语义建模和视觉生成的分工。其理解与生成的视觉表征也完全解耦,理解用 ViT 高层语义特征,生成用 VAE 浅层重建特征,避免冲突。
目前,InternVL-U 模型、数据管线与评测工具链均已开源,张鸿杰也呼吁社区一同参与到统一多模态模型的发展中来。

▲张鸿杰
6、商汤大装置卢国强:AI 系统的核心使用者,将从人转变为 Agent
商汤大装置产品总经理卢国强认为,行业正从“AI 原生”迈向“Agent 原生”新阶段,未来 AI 系统的核心使用者将从人转变为 Agent,交互方式、度量衡与安全边界将因此发生根本性变化,带来对 Agent 原生基础设施的需求。
从具体设计上来看,Agent 原生系统应让每一层都变得可发现、可理解、可操作。其中,算力层将由成本中心转变为利润中心,成为“收入工厂”;平台层则通过 token 统一度量衡,实现智能化与标准化;应用层需要实现“AI 赋能 AI”,使 AI 具备自主迭代能力。
基于此,商汤大装置在 2026 年将愿景从“AI 数字工厂”升级为“AI Token Factory”。这一工厂的原材料是算力、模型与数据,生产线是推理引擎、缓存与调度,产品是 token,其每一层都需要进行重新审视与设计,以更好服务 Agent 的需求。

▲卢国强
7、圆桌讨论:AI 下半场,大模型的演进与终局
大模型专题论坛的圆桌讨论由中信证券首席计算机行业分析师杨泽原主持,四位嘉宾分别是智谱 Z.ai 负责人李子玄、阿里云千问大模型解决方案资深总监王作书、上海 AI Lab 青年研究员张鸿杰、商汤大装置产品总经理卢国强。

▲从左到右:杨泽原、李子玄、王作书、张鸿杰、卢国强
4 位嘉宾先是结合自身背景谈了几个热点话题。
编程模型方面,李子玄谈道,在该领域保持领先的关键在于“品味”,也就是对技术趋势的判断力。对场景进行细致挖掘、通过 coding plan 等渠道获取反馈也很重要。
谈及全模态模型,王作书认为此类模型同时拥有“眼睛、嘴巴、耳朵”,将推动智能边界向三个方向拓展,分别是感知边界、推理边界和交互边界,最终在视频理解、自动驾驶、实时音视频交互提供更强的能力与更拟人的体验。
小尺寸多模态模型与大型原生多模态模型孰优孰劣?张鸿杰称,后者虽然架构优美,但训练代价大,也无法继承现有模型的能力。相比之下,前者可在其他模型基础上外扩生成编辑能力,性能上限也不低。小模型在数据方面的短板可以结合 Agent 补齐,不必单打独斗。
基础设施方面,卢国强分享说,尽管商汤大装置已经预判未来算力需求会大幅增长,但其增幅仍然远远超出预期。在推理时代,模型获得的输入要远大于模型的输出,这对基础设施的每一层都提出挑战,尤其是缓存效率。
嘉宾们也就几个共同话题分享了观点。
模型架构、能力和场景迭代方面,多模态、空间智能、长链路等被频繁提及。李子玄总结道,目前模型迭代的本质是智能提升和 token 效率优化的循环,新应用场景可能会因推理速度和稳定性的提升而迎来爆发。
年初的龙虾热让 Harness 走进主流视野。4 位嘉宾认为,Harness 可能会被模型逐渐内化,或是与具体行业和场景结合得更为密切。
王作书谈道,当前 Harness 是模型的放大器,但长期看会变成基础设施被隐藏,模型向下做深逻辑与工具调用能力,Harness 向上融入行业。张鸿杰觉得共生与内化是渐进过程,多模态的 Harness 比文本更具挑战。卢国强提出模型决定上限,而 Harness 决定下限,两者缺一不可。李子玄则预判,未来模型可能会自己“上发条”,不再依赖 Harness,人只负责补充上下文。
谈及厂商的全栈自主能力,几位嘉宾都认可其商业价值,但也不主张绝对化,而是要做好权衡与生态协同。全栈自主的落脚点最终仍是提供优质、稳定、高效的服务与商业价值。
08. 从“龙虾”、AI 眼镜到 token 管理,拆解国产智能体落地潮
在AI智能体专题论坛,8 位嘉宾分别从底层架构、技术演进、模型创新、硬件载体、垂直场景落地及企业级管控工具等方面,拆解智能体商业化路径。
从大厂打造的开源桌面级“龙虾”产品、智能体底层架构创新,到 AI 编程、AI 营销、AI 眼镜、token 管理等赛道,他们正在推动智能体更好地帮人们做事。
1、网易有道王宁:20 余天速成国内首个桌面级“龙虾”
网易有道 LobsterAI 项目负责人、智能硬件研发负责人王宁分享说,他们经过 20 余天快速打磨,2 月 19 日正式推出国内大厂的第一个开源桌面级“龙虾”LobsterAI。
其内部认为,OpenClaw 是 Agent 时代的 Linux 系统,因此他们将有道“龙虾”底层架构切换为 OpenClaw,上层保留自研 GUI 与业务流程,通过进程通信实现兼容。
他提到 Agent 产品的未来新机遇包括 Agent 向各领域渗透、Skill 即服务、开源生态共建、AI Native 工作流、多 Agent 协作、Agent 原生硬件等。

▲王宁
2、阶跃星辰袁微:Agent 技术核心转向外部环境构建
阶跃星辰算法专家袁微提到 AI Agent 的演进包括三个阶段,分别是提示词工程时代、上下文工程时代、Harness Engineering 时代,当下焦点已从模型本身转向构建完善外部运行环境,是 Agent 从 Demo 走向产品的关键。
当前处于 Agent 能力跃迁拐点,技术核心从模型竞赛转向系统工程与环境构建,Harness + OpenClaw 是将基础模型能力转化为企业级可交付 Agent 产品的关键方案。其中,Harness 是 Agent 的脚手架,对应系统层,OpenClaw 是 Agent 的调度引擎。

▲袁微
3、华为林炜哲:DLLM Agent 有望成为下一代 Agent 系统基石
华为中央研究院先进计算与存储实验室大模型算法专家林炜哲提到,Diffusion 模型在同等训练条件的智能体场景下,比 AR Agent 更快、规划更优、端到端效率更高。
他们研究发现,DLLM Agent 在同等序列长度、轮次约束下,能保持与 AR Agent 一致的任务精度,同时还能实现信息搜集调用量显著下降、任务拆分更精准、搜索轮次更少、耗时更短,叠加轻量采样算法可大幅提高精度,而 AR Agent 叠加复杂算法会显著增加消耗,进一步拉开性能差距。
林炜哲认为,DLLM Agent 有望成为下一代 Agent 系统重要基石。

▲林炜哲
4、雷鸟创新程思婕:两大判断定调眼镜是下一代AI最佳载体
如今智能眼镜进入爆发期,苹果、小米、阿里等大厂入局,赛道转向红海。雷鸟创新 AI 负责人程思婕抛出结论:眼镜是下一代 AI 的最佳载体。其两大判断依据是,眼镜是最佳的全域数据采集终端和随身智能体载体。
一方面,眼镜可以全天候贴身佩戴、无感采集第一人称交互数据、抢占物理世界原生数据入口,另一方面,其适配原生语音交互,支持一句话完成任务、打造个人随身外脑、下一代个性化推荐系统。
此外她认为,相较于机器人,智能眼镜作为 AI 载体的优势是,可以通过数据飞轮实现数据闭环与模型迭代,仅作为辅助决策的“外脑”,无需底层控制,从而规避机器人的数据瓶颈、底层控制难题。

▲程思婕
5、阿里云沈林:5 个准则打通 Agent 上下文环境数据构造
阿里云高级技术专家沈林分享了 EventHouse 实践的 5 个准则:
(1)Think like an Agent,给你的 Agent 足够的信息感知能力;
(2)给你的信息编写一本“图书馆馆藏目录”;
(3)知识不是“信息囤积”,和你的 Agent 做好“知识对账”;
(4)每次知识迭代都是一次生产级变更发布;
(5)“简单”、“可靠”不是锦上添花,而是很多行业的入场券。

▲沈林
6、极狐驭码宋健:AI Coding 已进入准交付级编程阶段
AI Coding 是 AI 技术落地的高价值入口,但目前市场上对 AI Coding 存在“玩具论”和“万能论”两大暴论。极狐驭码资深 AI 解决方案架构师宋健认为两种观点均有失偏颇,AI Coding 已进入准交付级编程阶段,有实用价值但仍需工程团队投入时间学习和实践。
AI Coding 智能体的五大关键技术是模式、规则、工作流、MCP、Skills,模式是将智能体预先划分成不同角色、规则是为智能体定规矩、工作流类似写脚本、MCP 是扩展智能体能力的工具箱、Skills 是原子化的功能插件,协同用好这些关键技术和功能是企业实施 AI Coding 的关键。

▲宋健
7、Noumena AI 赵欢:AI 营销增长潜力仅次于编程
Noumena AI(物自体科技)联合创始人、产品算法负责人赵欢的判断是,营销是仅次于 AI Coding领域的爆发式增长场景,且与 Coding 场景逻辑完全不同。
营销场景面临数据割裂、人员流失导致经验丢失、平台算法迭代快、品牌方难以适配等痛点。Noumena AI 推出了营销行业的龙虾产品 GrowClaw,不仅能解决典型的营销问题比如内容洞察,达人筛选,内容运营,投流分享等,还可以适配持续维护状态、持续更新、多方协作的营销业务系统。
针对 OpenClaw 稳定性差、非技术用户上手难问题,赵欢称他们在内部打造了“龙虾医院”和“龙虾学院”,以实现 Agent 故障自动诊断以及 AI 自动学习、快速为业务提供 Skill 等。

▲赵欢
8、清程极智李浩瑞:首发企业级 token 管理工具,即将开源
清程极智技术专家李浩瑞首次正式发布了其企业级 token 管理新品 ATM(Agent Token Manager),该产品后续将开源。
ATM 的核心功能是本地聚合网关、Agent 身份级管控、智能路由下放、本地数据存储、Agent 原生适配,他们实测显示,本地网关融合云端、本地大模型后使得成本降低 70%。
为了帮助企业在AI转型中进行 token 管控与质量追踪,清程极智的 AI Ping 可以在 MaaS 层通过持续模型服务评测,提供高质量低价格 token;ATM 是本地网关,在本地通过 Agent 身份级管控实现精细化企业内部治理。

▲李浩瑞
9、圆桌讨论:OpenClaw x Harness Engineering,AI 智能体的范式革命
圆桌讨论环节由智东西联合创始人、智猩猩总经理何峰主持,四位嘉宾分别是阶跃星辰算法专家袁微,雷鸟创新 AI 负责人程思婕,清程极智技术专家李浩瑞,Noumena AI(物自体科技)联合创始人、产品算法负责人赵欢。
嘉宾们探讨了当下 OpenClaw 与 Hermes Agent 之间的“养虾、养马”争论、Skill 是否会吃掉 App 等诸多热点话题。

▲从左到右:何峰、袁微、程思婕、李浩瑞、赵欢
袁微站在模型团队角度称,OpenClaw 开启了AI智能体爆发元年,当下 Agent 实现生产级交付的最大瓶颈是模型研发,因为市面上的通用 Benchmark 很难对应每个人需求,因此他们试图通过收集专家意见、用户的实际体验、自建 Benchmark 等方式,让模型体验和大多数人体感保持一致。
作为硬件厂商的代表,程思婕认为 Skills 会逐步替代 App,而当下 Skill 变成 App 的壁垒在生态层面,需要大厂开放自己的原子能力。围绕 OpenClaw 与眼镜的结合,雷鸟创新制定了三步战略,第一步是面向开发者,让眼镜作为输入入口快速接入OpenClaw,第二步打通 App 让其丝滑连接 Agent,第三步是内部自研类似框架。
作为 Token 服务商,李浩瑞提到一个现象,Hermes Agent 出来后,OpenClaw 的 Token 消耗在下降,这进一步说明,越来越聪明、越来越懂用户的 Agent 是技术上的大趋势。企业内部管理 Token 的最大难点,就是不知道 Token 消耗流去了哪里,这也是他们打造本地 Token 管理工具的原因。
在营销这一垂类场景,赵欢认为,OpenClaw 是产品形态革新,能大幅降低非技术人群 AI 使用门槛,未来模型会逐步吃掉 Harness,垂类厂商需构建领域护城河。他们判断一个场景是否真正适合 Agent 落地的两个视角是,本身的技术场景匹配度,以及场景商业价值、落地困难程度。
09. 结语:生成式 AI 产业开始,告别“早期阶段”
今年 AI 产业依然在飞速变化。年初的“养龙虾”热潮带动 token 消耗量爆发,密集迭代的各类大模型持续带来新的惊喜,业界已经对基准测试分数祛魅,转而更看重真实的任务完成度,新一轮AI基建潮正如火如荼开展。
被业界期盼已久的 DeepSeek-V4,也交出了一份具有开创意义的答卷:不仅继续做到大幅压低成本和性能领先,而且写出了一个打破海外芯片依赖的新叙事。
这场空前的产业爆发之中,还有一些需要面对的问题。
模型迭代速度之快,正在给企业用户带来选择疲劳。相比追逐新模型,企业更需要的是建立与模型无关的架构能力。
模型能力与安全的矛盾也在激化。Anthropic 手握强大的 Mythos 模型却不敢全面发布,ChatGPT Images 2.0 生成的图像已经以假乱真,其他旗舰模型同样面临网络安全风险的审慎评估。前沿能力的发布正成为一个越来越沉重的决策。
与此同时,炒作性宣传和情绪生意也在侵蚀行业的判断力,真正的技术进展反而被淹没在噪声之中。在 DeepSeek-V4 新闻稿的结尾,有一句引自《荀子》的名言:“不诱于誉,不恐于诽,率道而行,端然正己。”也愿生成式AI道路上的前行者们,都有类似的定力。
而 AI 产品最终需要以真实的商业回报来验证。头部企业交出了快速增长的收入成绩单,同时也在寻求巨额算力资源采购,但这种支出比收入增长更快的模式会持续多久,答案要等到新一代基础设施真正投入运营之后才能揭晓。
AI 正在不可逆转地走向产业化,开始触及软件开发、知识工作和人机交互的底层范式。但截至目前,这个新型技术产业仍处于地基浇筑期,至于最终建成的大厦是什么模样,可能连建设者自己都还无法完全想象。
2026 年这个春天,生成式 AI 产业开始告别它的“早期阶段”。
文章信息来自于智东西,不代表白鲸出海官方立场,内容仅供网友参考学习。对于因本网站内容所引起的纠纷、损失等,白鲸出海均不承担侵权行为的连带责任。如若转载请联系原出处。
友情提醒:白鲸出海目前仅有微信群与QQ群,并无在Telegram等其他社交软件创建群,请白鲸的广大用户、合作伙伴警惕他人冒充我们,向您索要费用、骗取钱财!

扫一扫 在手机阅读、分享本文
扫一扫 在手机阅读、分享本文















 闽公网安备35010402350923号
闽公网安备35010402350923号